![]()
(2022) DP-200 Dumps and Practice Test (242 Questions)
Guide (New 2022) Actual Microsoft DP-200 Exam Questions
What is the duration of the DP-200 Exam
- Passing Score: 700/1000
- Format: Multiple choices, multiple answers
- Length of Examination: 150 minutes
- Number of Questions: 45-60
For more info visit:
Microsoft DP-200 Exam Reference
NEW QUESTION 42
A company runs Microsoft Dynamics CRM with Microsoft SQL Server on-premises. SQL Server Integration Services (SSIS) packages extract data from Dynamics CRM APIs, and load the data into a SQL Server data warehouse.
The datacenter is running out of capacity. Because of the network configuration, you must extract on premises data to the cloud over https. You cannot open any additional ports. The solution must implement the least amount of effort.
You need to create the pipeline system.
Which component should you use? To answer, select the appropriate technology in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: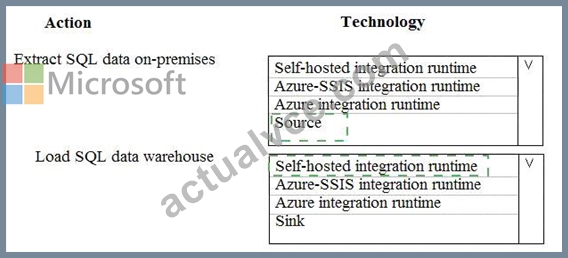
Explanation
Box 1: Source
For Copy activity, it requires source and sink linked services to define the direction of data flow.
Copying between a cloud data source and a data source in private network: if either source or sink linked service points to a self-hosted IR, the copy activity is executed on that self-hosted Integration Runtime.
Box 2: Self-hosted integration runtime
A self-hosted integration runtime can run copy activities between a cloud data store and a data store in a private network, and it can dispatch transform activities against compute resources in an on-premises network or an Azure virtual network. The installation of a self-hosted integration runtime needs on an on-premises machine or a virtual machine (VM) inside a private network.
References:
https://docs.microsoft.com/en-us/azure/data-factory/create-self-hosted-integration-runtime
NEW QUESTION 43
You plan to create a dimension table in Azure Data Warehouse that will be less than 1 GB.
You need to create the table to meet the following requirements:
Provide the fastest query time.
Minimize data movement.
Which type of table should you use?
- A. hash distributed
- B. replicated
- C. round-robin
- D. heap
Answer: C
Explanation:
Usually common dimension tables or tables that doesn't distribute evenly are good candidates for round-robin distributed table.
Note: Dimension tables or other lookup tables in a schema can usually be stored as round-robin tables.
Usually these tables connect to more than one fact tables and optimizing for one join may not be the best idea.
Also usually dimension tables are smaller which can leave some distributions empty when hash distributed.
Round-robin by definition guarantees a uniform data distribution.
References:
https://blogs.msdn.microsoft.com/sqlcat/2015/08/11/choosing-hash-distributed-table-vs-round-robindistributed-table-in-azure-sql-dw-service/
NEW QUESTION 44
You need to ensure that Azure Data Factory pipelines can be deployed. How should you configure authentication and authorization for deployments? To answer, select the appropriate options in the answer choices.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: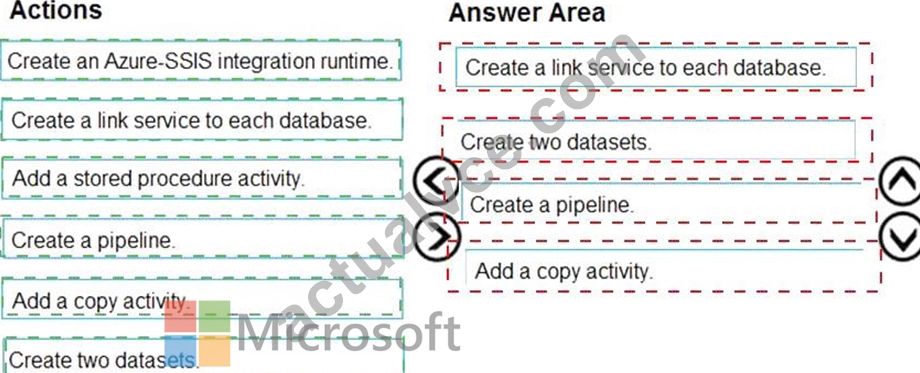
Explanation
The way you control access to resources using RBAC is to create role assignments. This is a key concept to understand - it's how permissions are enforced. A role assignment consists of three elements: security principal, role definition, and scope.
Scenario:
No credentials or secrets should be used during deployments
Phone-based poll data must only be uploaded by authorized users from authorized devices Contractors must not have access to any polling data other than their own Access to polling data must set on a per-active directory user basis References:
https://docs.microsoft.com/en-us/azure/role-based-access-control/overview
Topic 3, Litware, inc
Overview
General Overview
Litware, Inc, is an international car racing and manufacturing company that has 1,000 employees. Most employees are located in Europe. The company supports racing teams that complete in a worldwide racing series.
Physical Locations
Litware has two main locations: a main office in London, England, and a manufacturing plant in Berlin, Germany.
During each race weekend, 100 engineers set up a remote portable office by using a VPN to connect the datacentre in the London office. The portable office is set up and torn down in approximately 20 different countries each year.
Existing environment
Race Central
During race weekends, Litware uses a primary application named Race Central. Each car has several sensors that send real-time telemetry data to the London datacentre. The data is used for real-time tracking of the cars.
Race Central also sends batch updates to an application named Mechanical Workflow by using Microsoft SQL Server Integration Services (SSIS).
The telemetry data is sent to a MongoDB database. A custom application then moves the data to databases in SQL Server 2017. The telemetry data in MongoDB has more than 500 attributes. The application changes the attribute names when the data is moved to SQL Server 2017.
The database structure contains both OLAP and OLTP databases.
Mechanical Workflow
Mechanical Workflow is used to track changes and improvements made to the cars during their lifetime.
Currently, Mechanical Workflow runs on SQL Server 2017 as an OLAP system.
Mechanical Workflow has a named Table1 that is 1 TB. Large aggregations are performed on a single column of Table 1.
Requirements
Planned Changes
Litware is the process of rearchitecting its data estate to be hosted in Azure. The company plans to decommission the London datacentre and move all its applications to an Azure datacentre.
Technical Requirements
Litware identifies the following technical requirements:
* Data collection for Race Central must be moved to Azure Cosmos DB and Azure SQL Database. The data must be written to the Azure datacentre closest to each race and must converge in the least amount of time.
* The query performance of Race Central must be stable, and the administrative time it takes to perform optimizations must be minimized.
* The datacentre for Mechanical Workflow must be moved to Azure SQL data Warehouse.
* Transparent data encryption (IDE) must be enabled on all data stores, whenever possible.
* An Azure Data Factory pipeline must be used to move data from Cosmos DB to SQL Database for Race Central. If the data load takes longer than 20 minutes, configuration changes must be made to Data Factory.
* The telemetry data must migrate toward a solution that is native to Azure.
* The telemetry data must be monitored for performance issues. You must adjust the Cosmos DB Request Units per second (RU/s) to maintain a performance SLA while minimizing the cost of the Ru/s.
Data Masking Requirements
During rare weekends, visitors will be able to enter the remote portable offices. Litware is concerned that some proprietary information might be exposed. The company identifies the following data masking requirements for the Race Central data that will be stored in SQL Database:
* Only show the last four digits of the values in a column named SuspensionSprings.
* Only Show a zero value for the values in a column named ShockOilWeight.
NEW QUESTION 45
Contoso, Ltd. plans to configure existing applications to use Azure SQL Database.
When security-related operations occur, the security team must be informed.
You need to configure Azure Monitor while minimizing administrative efforts.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Use all Azure SQL Database servers as a resource.
- B. Query audit log entries as a condition.
- C. Use all security operations as a condition.
- D. Use [email protected] as an alert email address.
- E. Create a new action group to email [email protected].
Answer: A,C,E
Explanation:
Explanation/Reference:
References:
https://docs.microsoft.com/en-us/azure/azure-monitor/platform/alerts-action-rules
NEW QUESTION 46
Your company uses Azure SQL Database and Azure Blob storage.
All data at rest must be encrypted by using the company's own key. The solution must minimize administrative effort and the impact to applications which use the database.
You need to configure security.
What should you implement? To answer, select the appropriate option in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
References:
https://docs.microsoft.com/en-us/azure/sql-database/transparent-data-encryption-azure-sql
https://docs.microsoft.com/en-us/azure/storage/common/storage-service-encryption
NEW QUESTION 47
You develop data engineering solutions for a company. The company has on-premises Microsoft SQL Server databases at multiple locations.
The company must integrate data with Microsoft Power BI and Microsoft Azure Logic Apps. The solution must avoid single points of failure during connection and transfer to the cloud. The solution must also minimize latency.
You need to secure the transfer of data between on-premises databases and Microsoft Azure.
What should you do?
- A. Install an Azure on-premises data gateway as a cluster at each location
- B. Install a standalone on-premises Azure data gateway at each location
- C. Install an on-premises data gateway in personal mode at each location
- D. Install an Azure on-premises data gateway at the primary location
Answer: A
Explanation:
Explanation
You can create high availability clusters of On-premises data gateway installations, to ensure your organization can access on-premises data resources used in Power BI reports and dashboards. Such clusters allow gateway administrators to group gateways to avoid single points of failure in accessing on-premises data resources. The Power BI service always uses the primary gateway in the cluster, unless it's not available. In that case, the service switches to the next gateway in the cluster, and so on.
References:
https://docs.microsoft.com/en-us/power-bi/service-gateway-high-availability-clusters
NEW QUESTION 48
Your company manages on-premises Microsoft SQL Server pipelines by using a custom solution.
The data engineering team must implement a process to pull data from SQL Server and migrate it to Azure Blob storage. The process must orchestrate and manage the data lifecycle.
You need to configure Azure Data Factory to connect to the on-premises SQL Server database.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation: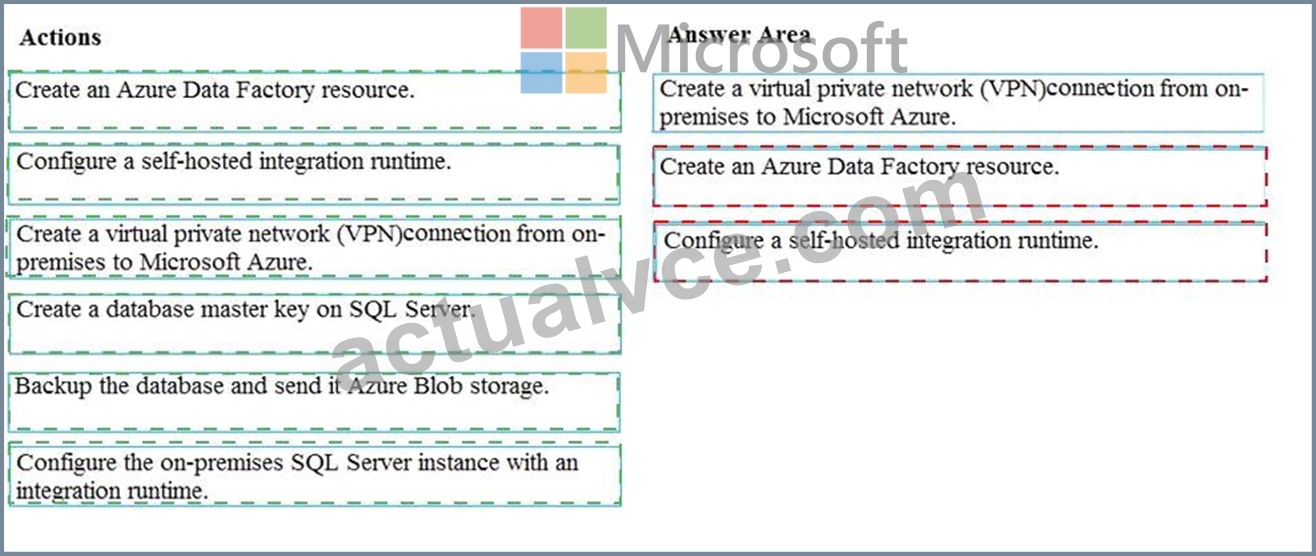
Explanation
Step 1: Create a virtual private network (VPN) connection from on-premises to Microsoft Azure.
You can also use IPSec VPN or Azure ExpressRoute to further secure the communication channel between your on-premises network and Azure.
Azure Virtual Network is a logical representation of your network in the cloud. You can connect an on-premises network to your virtual network by setting up IPSec VPN (site-to-site) or ExpressRoute (private peering).
Step 2: Create an Azure Data Factory resource.
Step 3: Configure a self-hosted integration runtime.
You create a self-hosted integration runtime and associate it with an on-premises machine with the SQL Server database. The self-hosted integration runtime is the component that copies data from the SQL Server database on your machine to Azure Blob storage.
Note: A self-hosted integration runtime can run copy activities between a cloud data store and a data store in a private network, and it can dispatch transform activities against compute resources in an on-premises network or an Azure virtual network. The installation of a self-hosted integration runtime needs on an on-premises machine or a virtual machine (VM) inside a private network.
References:
https://docs.microsoft.com/en-us/azure/data-factory/tutorial-hybrid-copy-powershell
NEW QUESTION 49
You have an ASP.NET web app that uses an Azure SQL database. The database contains a table named Employee. The table contains sensitive employee information, including a column named DateOfBirth.
You need to ensure that the data in the DateOfBirth column is encrypted both in the database and when transmitted between a client and Azure. Only authorized clients must be able to view the data in the column.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions in the answer area and arrange them in the correct order.
Answer:
Explanation: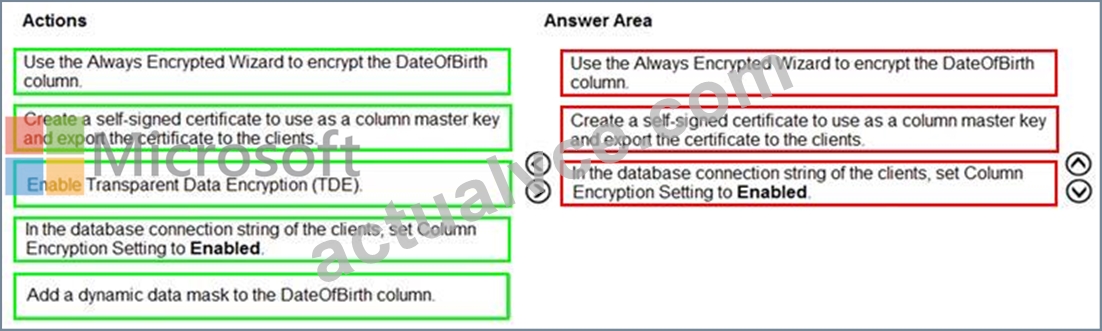
Reference:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-always-encrypted
NEW QUESTION 50
You have a SQL pool in Azure Synapse.
You discover that some queries fail or take a long time to complete.
You need to monitor for transactions that have rolled back.
Which dynamic management view should you query?
- A. sys.dm_pdw_waits
- B. sys.dm_pdw_nodes_tran_database_transactions
- C. sys.dm_pdw_exec_sessions
- D. sys.dm_pdw_request_steps
Answer: B
Explanation:
Explanation
You can use Dynamic Management Views (DMVs) to monitor your workload including investigating query execution in SQL pool.
If your queries are failing or taking a long time to proceed, you can check and monitor if you have any transactions rolling back.
Example:
-- Monitor rollback
SELECT
SUM(CASE WHEN t.database_transaction_next_undo_lsn IS NOT NULL THEN 1 ELSE 0 END), t.pdw_node_id, nod.[type] FROM sys.dm_pdw_nodes_tran_database_transactions t JOIN sys.dm_pdw_nodes nod ON t.pdw_node_id = nod.pdw_node_id GROUP BY t.pdw_node_id, nod.[type] Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-managemonito monitor-transaction-log-rollback
NEW QUESTION 51
You develop data engineering solutions for a company.
A project requires analysis of real-time Twitter feeds. Posts that contain specific keywords must be stored and processed on Microsoft Azure and then displayed by using Microsoft Power BI. You need to implement the solution.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.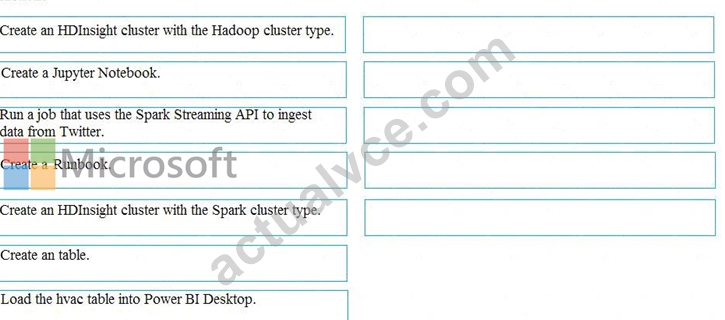
Answer:
Explanation: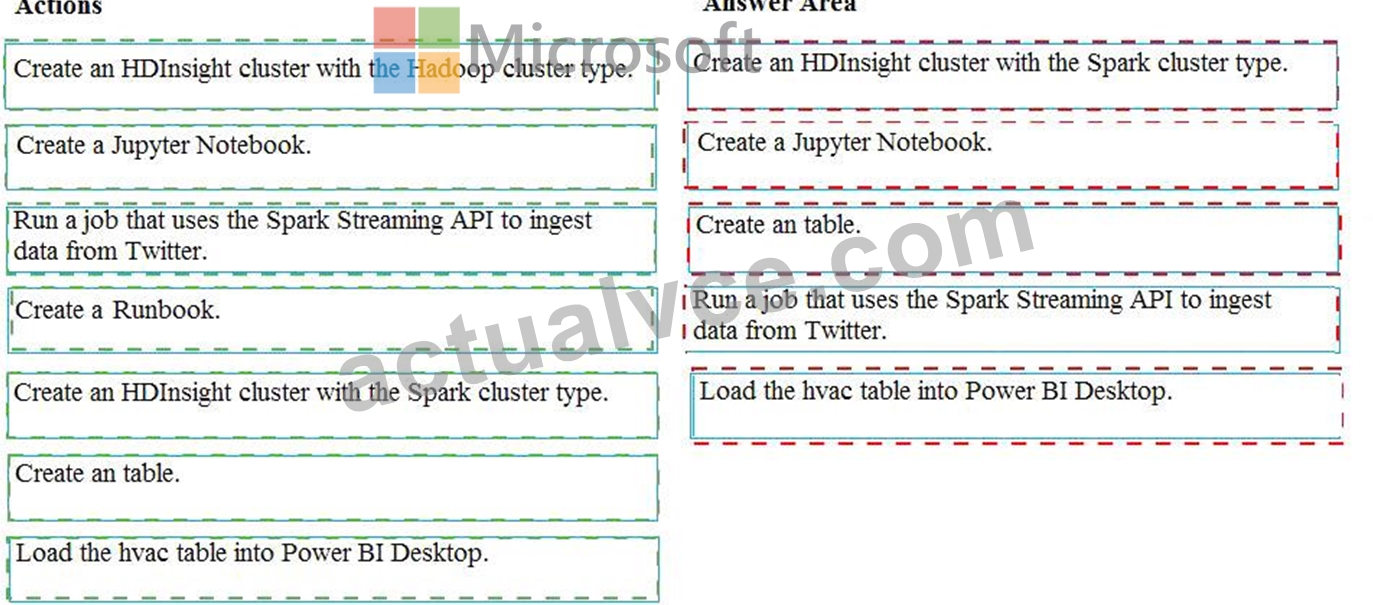
Explanation
Step 1: Create an HDInisght cluster with the Spark cluster type
Step 2: Create a Jyputer Notebook
Step 3: Create a table
The Jupyter Notebook that you created in the previous step includes code to create an hvac table.
Step 4: Run a job that uses the Spark Streaming API to ingest data from Twitter Step 5: Load the hvac table into Power BI Desktop You use Power BI to create visualizations, reports, and dashboards from the Spark cluster data.
References:
https://acadgild.com/blog/streaming-twitter-data-using-spark
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-use-with-data-lake-store
NEW QUESTION 52
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure subscription that contains an Azure Storage account.
You plan to implement changes to a data storage solution to meet regulatory and compliance standards.
Every day, Azure needs to identify and delete blobs that were modified during the last 100 days.
Solution: You apply an expired tag to the blobs in the storage account.
Does this meet the goal?
- A. No
- B. Yes
Answer: A
Explanation:
Explanation
Instead apply an Azure Blob storage lifecycle policy.
Reference:
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-lifecycle-management-concepts?tabs=azure-porta
NEW QUESTION 53
You need to ensure that Azure Data Factory pipelines can be deployed. How should you configure authentication and authorization for deployments? To answer, select the appropriate options in the answer choices.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
The way you control access to resources using RBAC is to create role assignments. This is a key concept to understand - it's how permissions are enforced. A role assignment consists of three elements: security principal, role definition, and scope.
Scenario:
No credentials or secrets should be used during deployments
Phone-based poll data must only be uploaded by authorized users from authorized devices
Contractors must not have access to any polling data other than their own
Access to polling data must set on a per-active directory user basis
References:
https://docs.microsoft.com/en-us/azure/role-based-access-control/overview
Topic 2, Contoso Ltd
Overview
Current environment
Contoso relies on an extensive partner network for marketing, sales, and distribution. Contoso uses external companies that manufacture everything from the actual pharmaceutical to the packaging.
The majority of the company's data reside in Microsoft SQL Server database. Application databases fall into one of the following tiers:
The company has a reporting infrastructure that ingests data from local databases and partner services. Partners services consists of distributors, wholesales, and retailers across the world. The company performs daily, weekly, and monthly reporting.
Requirements
Tier 3 and Tier 6 through Tier 8 application must use database density on the same server and Elastic pools in a cost-effective manner.
Applications must still have access to data from both internal and external applications keeping the data encrypted and secure at rest and in transit.
A disaster recovery strategy must be implemented for Tier 3 and Tier 6 through 8 allowing for failover in the case of server going offline.
Selected internal applications must have the data hosted in single Microsoft Azure SQL Databases.
* Tier 1 internal applications on the premium P2 tier
* Tier 2 internal applications on the standard S4 tier
The solution must support migrating databases that support external and internal application to Azure SQL Database. The migrated databases will be supported by Azure Data Factory pipelines for the continued movement, migration and updating of data both in the cloud and from local core business systems and repositories.
Tier 7 and Tier 8 partner access must be restricted to the database only.
In addition to default Azure backup behavior, Tier 4 and 5 databases must be on a backup strategy that performs a transaction log backup eve hour, a differential backup of databases every day and a full back up every week.
Back up strategies must be put in place for all other standalone Azure SQL Databases using Azure SQL-provided backup storage and capabilities.
Databases
Contoso requires their data estate to be designed and implemented in the Azure Cloud. Moving to the cloud must not inhibit access to or availability of data.
Databases:
Tier 1 Database must implement data masking using the following masking logic:
Tier 2 databases must sync between branches and cloud databases and in the event of conflicts must be set up for conflicts to be won by on-premises databases.
Tier 3 and Tier 6 through Tier 8 applications must use database density on the same server and Elastic pools in a cost-effective manner.
Applications must still have access to data from both internal and external applications keeping the data encrypted and secure at rest and in transit.
A disaster recovery strategy must be implemented for Tier 3 and Tier 6 through 8 allowing for failover in the case of a server going offline.
Selected internal applications must have the data hosted in single Microsoft Azure SQL Databases.
* Tier 1 internal applications on the premium P2 tier
* Tier 2 internal applications on the standard S4 tier
Reporting
Security and monitoring Security
A method of managing multiple databases in the cloud at the same time is must be implemented to streamlining data management and limiting management access to only those requiring access.
Monitoring
Monitoring must be set up on every database. Contoso and partners must receive performance reports as part of contractual agreements.
Tiers 6 through 8 must have unexpected resource storage usage immediately reported to data engineers.
The Azure SQL Data Warehouse cache must be monitored when the database is being used. A dashboard monitoring key performance indicators (KPIs) indicated by traffic lights must be created and displayed based on the following metrics:
Existing Data Protection and Security compliances require that all certificates and keys are internally managed in an on-premises storage.
You identify the following reporting requirements:
* Azure Data Warehouse must be used to gather and query data from multiple internal and external Title
databases
* Azure Data Warehouse must be optimized to use data from a cache
* Reporting data aggregated for external partners must be stored in Azure Storage and be made available during regular business hours in the connecting regions
* Reporting strategies must be improved to real time or near real time reporting cadence to improve competitiveness and the general supply chain
* Tier 9 reporting must be moved to Event Hubs, queried, and persisted in the same Azure region as the company's main office
* Tier 10 reporting data must be stored in Azure Blobs
Issues
Team members identify the following issues:
* Both internal and external client application run complex joins, equality searches and group-by clauses. Because some systems are managed externally, the queries will not be changed or optimized by Contoso
* External partner organization data formats, types and schemas are controlled by the partner companies
* Internal and external database development staff resources are primarily SQL developers familiar with the Transact-SQL language.
* Size and amount of data has led to applications and reporting solutions not performing are required speeds
* Tier 7 and 8 data access is constrained to single endpoints managed by partners for access
* The company maintains several legacy client applications. Data for these applications remains isolated form other applications. This has led to hundreds of databases being provisioned on a per application basis
NEW QUESTION 54
You manage an enterprise data warehouse in Azure Synapse Analytics.
Users report slow performance when they run commonly used queries. Users do not report performance changes for infrequently used queries.
You need to monitor resource utilization to determine the source of the performance issues.
Which metric should you monitor?
- A. Cache hit percentage
- B. Data Warehouse Units (DWU) used
- C. DWU limit
- D. Data IO percentage
Answer: A
Explanation:
Explanation
The Azure Synapse Analytics storage architecture automatically tiers your most frequently queried columnstore segments in a cache residing on NVMe based SSDs designed for Gen2 data warehouses. Greater performance is realized when your queries retrieve segments that are residing in the cache. You can monitor and troubleshoot slow query performance by determining whether your workload is optimally leveraging the Gen2 cache.
Note: As of November 2019, Azure SQL Data Warehouse is now Azure Synapse Analytics.
Reference:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-how-to-monitor-cache
https://docs.microsoft.com/bs-latn-ba/azure/sql-data-warehouse/sql-data-warehouse-concept-resource-utilizatio
NEW QUESTION 55
You need to collect application metrics, streaming query events, and application log messages for an Azure Databrick cluster.
Which type of library and workspace should you implement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.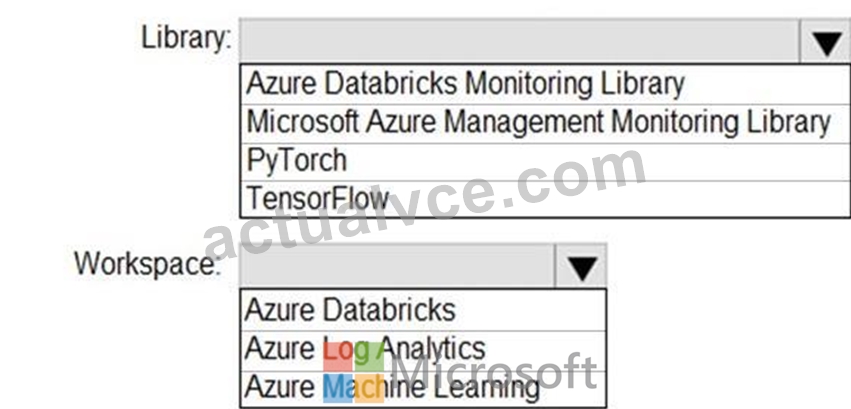
Answer:
Explanation:
Explanation
You can send application logs and metrics from Azure Databricks to a Log Analytics workspace. It uses the Azure Databricks Monitoring Library, which is available on GitHub.
References:
https://docs.microsoft.com/en-us/azure/architecture/databricks-monitoring/application-logs
NEW QUESTION 56
You have an Azure SQL database that contains a table named Customer. Customer contains the columns shown in the following table.
You apply a masking rule as shown in the following table.
Which users can view the email addresses of the customers?
- A. Server administrators only.
- B. Server administrators and all users who are granted the SELECT permission to the Customer_Email column only.
- C. Server administrators and all users who are granted the UNMASK permission to the Customer_Email column only.
- D. All users who are granted the UNMASK permission to the Customer_Email column only.
Answer: D
Explanation:
Explanation
Grant the UNMASK permission to a user to enable them to retrieve unmasked data from the columns for which masking is defined.
Reference:
https://docs.microsoft.com/en-us/sql/relational-databases/security/dynamic-data-masking
NEW QUESTION 57
You are a data engineer. You are designing a Hadoop Distributed File System (HDFS) architecture. You plan to use Microsoft Azure Data Lake as a data storage repository.
You must provision the repository with a resilient data schema. You need to ensure the resiliency of the Azure Data Lake Storage. What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
Box 1: NameNode
An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients.
Box 2: DataNode
The DataNodes are responsible for serving read and write requests from the file system's clients.
Box 3: DataNode
The DataNodes perform block creation, deletion, and replication upon instruction from the NameNode.
Note: HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system's clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
References:
https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html#NameNode+and+DataNodes
NEW QUESTION 58
......
The benefit in Obtaining the DP-200 Exam Certification
- When Candidates applying for a job or looking to promotion in their current position, a Microsoft Certified Azure Data Engineer Associate certification in the field in which Candidates are applying will put you at the top of the list and make them a desirable candidate for employers.
- After completion of Microsoft Certified Azure Data Engineer, Associate Certification candidates receive official confirmation from Microsoft that you are now fully certified in their chosen field. This can be now added to their CV, cover letters and job applications.
- Organization owners invest a lot in their employees when it comes to their training with the goal of making them quicker, more efficient, and more knowledgeable about their role. Certified Professional will reduce the time he spends on tasks, meaning he can get more done this could help reduce company downtime when repairing faults on a system or fixing hardware problems.
- Candidates will get in-depth knowledge by completing the courses along with the access to revision materials for 6 months upon completion means they will have a wider skill set when it comes to the various technologies and systems than an uncertified professional. Certified Professional in this particular skill set is 74% more efficient when it comes to completing their tasks in a timely well-executed manner.
- Becoming Microsoft Certified Azure Data Engineer Associate means one thing you are worth more to the company and therefore more to yourself in the form of an upgraded pay package. On average a Microsoft Certified Azure Data Engineer Associate member of staff is estimated to be worth 30% more to a company than their uncertified professionals.
DP-200 Exam Dumps Pass with Updated 2022 Certified Exam Questions: https://www.actualvce.com/Microsoft/DP-200-valid-vce-dumps.html